
5 Key Competitor Tracking API Mistakes in Custom Software Development
Why Competitor Tracking APIs Are Tricky (and How to Get Them Right)
Building custom software to track competitors’ moves—pricing changes, product launches, legal updates—is a powerful strategy. But it only works if your API integrations are solid. Even small mistakes can lead to data gaps, security breaches, or broken workflows. Below are five common pitfalls and how to avoid them.
But first, let’s look at the kind of intelligence you could be collecting. Real competitor insights—like the ones RivalSense surfaces weekly—can transform your strategy.
Real-World Competitor Insights You Could Be Missing
Knowing what your competitors are actually doing is the whole point. Here are three real examples of changes that matter—and why they’re valuable.
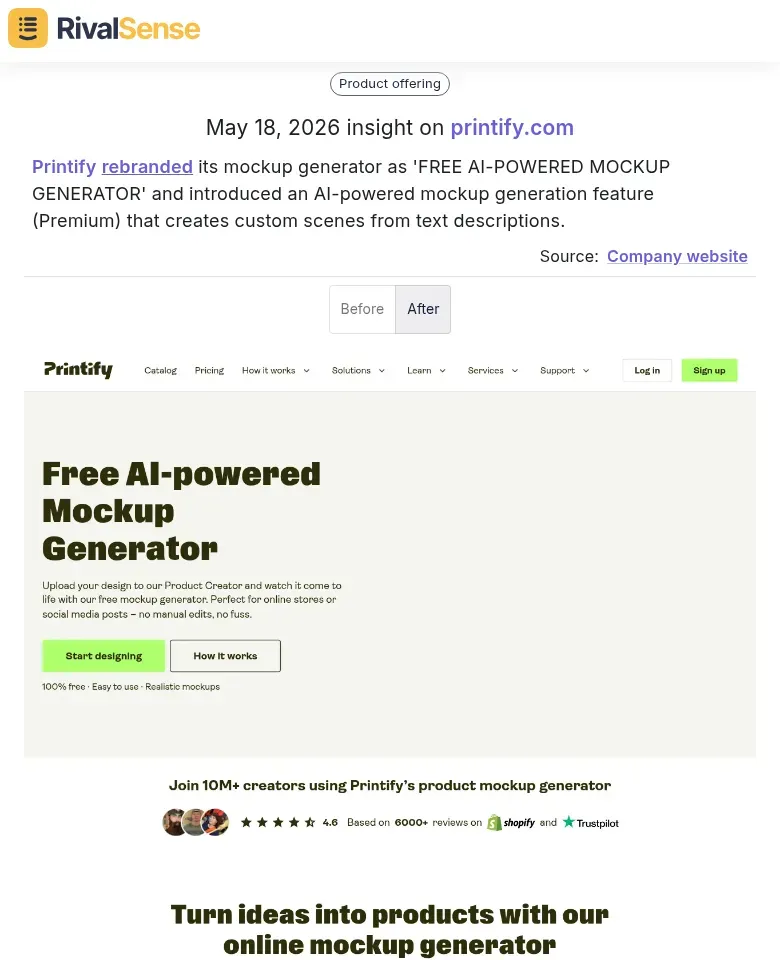
🔹 Printify rebranded its mockup generator as “FREE AI-POWERED MOCKUP GENERATOR” and introduced an AI-powered feature that creates custom scenes from text descriptions. Why this matters: Product feature changes signal new value propositions. If you track this, you can adjust your messaging or build a counter-feature.
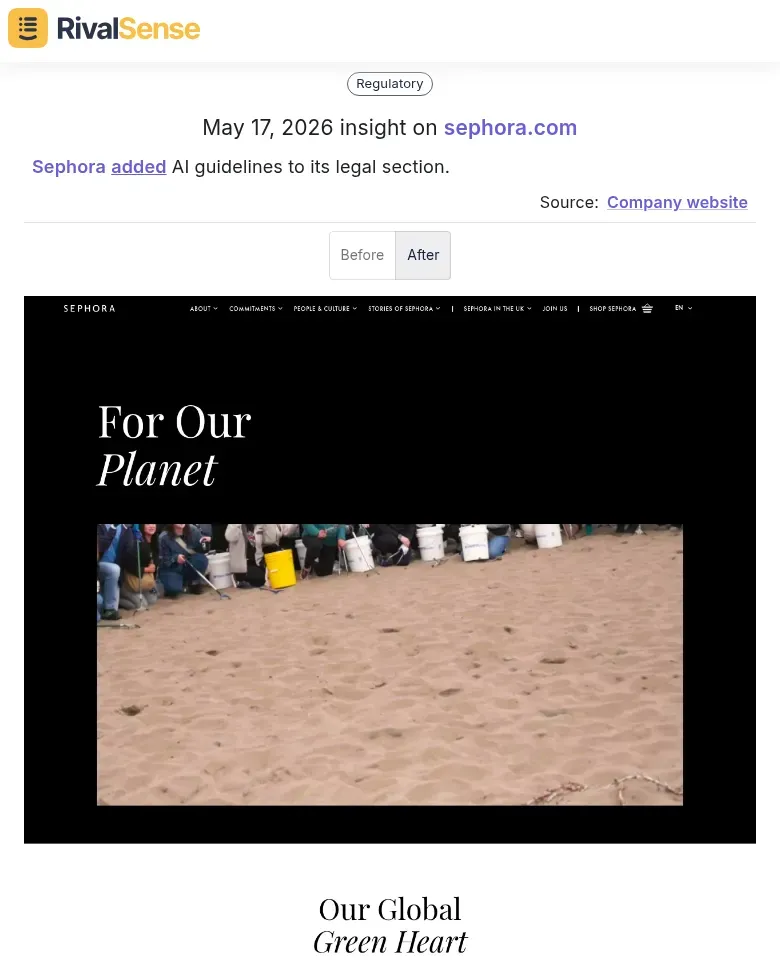
🔹 Sephora added AI guidelines to its legal section. Why this matters: Regulatory and legal updates reveal compliance shifts. For B2B companies, tracking competitor legal changes helps you anticipate industry standards and avoid fines.
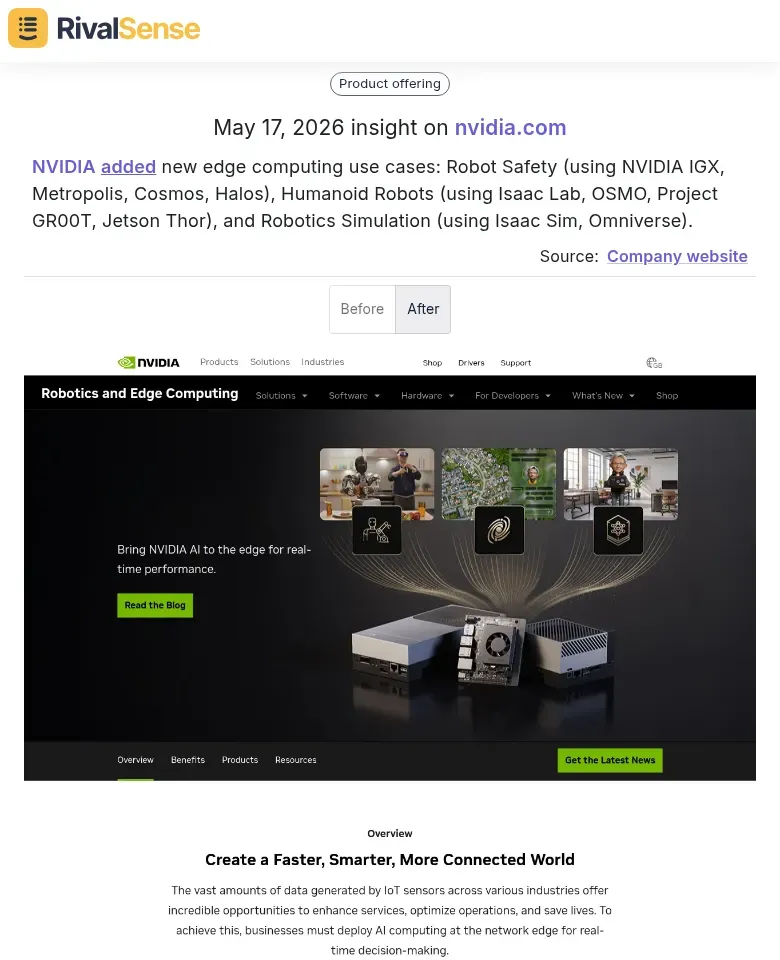
🔹 NVIDIA added new edge computing use cases, including Robot Safety, Humanoid Robots, and Robotics Simulation. Why this matters: New product lines and use cases show where a competitor is investing R&D. This can inform your own product roadmap or partnership strategy.
These examples come from RivalSense, which tracks product launches, pricing updates, partnerships, and more across websites, social media, and registries—delivered weekly.
Now, let’s dive into the API mistakes that can prevent you from capturing insights like these.
Mistake #1: Ignoring Rate Limits and Throttling
Underestimating API rate limits is a common pitfall that can lead to data gaps and service disruptions. When your custom software exceeds the allowed number of requests, the provider may throttle or block your access entirely, leaving you with incomplete competitor data.
Why It Hurts:
- Data Gaps: Missing updates mean you lose sight of competitor moves.
- IP Bans/Account Suspension: Aggressive requests can trigger permanent blocks.
Best Practices:
- Monitor Usage: Log response headers like
X-RateLimit-Remainingand set alerts when approaching limits. - Implement Exponential Backoff: On receiving a
429 Too Many Requestsresponse, wait and retry with increasing delays (e.g., 1s, 2s, 4s, 8s…). - Build Adaptive Queues: Use a queue system that respects rate limits—schedule requests evenly over time and pause when limits are near.
Quick Checklist:
- [ ] Read the API’s rate limit documentation.
- [ ] Add retry logic with exponential backoff.
- [ ] Set up monitoring for rate limit headers.
- [ ] Use a request queue with configurable throughput.
By respecting rate limits, you ensure consistent, reliable data flow without risking access suspension.
Mistake #2: Neglecting Authentication and Security
Hardcoding API keys or tokens directly into source code is a critical error when building custom competitor tracking software. This exposes sensitive competitor data to anyone with repository access—whether internal developers or external attackers. Even in private repos, leaked credentials can lead to data breaches, legal liability, and loss of competitive intelligence.
Common Pitfalls:
- Storing API keys in config files committed to version control.
- Using long-lived static tokens without rotation.
- Ignoring OAuth 2.0 flows for delegated access.
Secure Authentication Checklist:
- Never hardcode secrets – Use environment variables or a secrets manager (e.g., AWS Secrets Manager, HashiCorp Vault).
- Implement OAuth 2.0 – For third-party APIs, use authorization code flow with refresh tokens.
- Rotate secrets regularly – Set automated rotation policies (e.g., every 90 days) and invalidate old keys immediately.
- Use short-lived tokens – Prefer JWTs with expiration times (e.g., 15 minutes) over static API keys.
- Encrypt at rest and in transit – Always use HTTPS and encrypt stored credentials.
Pro Tip: Add a pre-commit hook to scan for hardcoded secrets (e.g., using git-secrets or truffleHog). For multi-environment setups, inject credentials via CI/CD pipelines rather than hardcoding them per environment. By treating authentication as a first-class security concern, you protect your competitive data and maintain trust with stakeholders.
Mistake #3: Overlooking Data Schema Changes
APIs evolve, often without notice. Hardcoded field mappings in your competitor tracking integration are a ticking time bomb. When the API provider adds, renames, or removes a field, your integration breaks silently—no data flows, but no error alerts either. This is especially dangerous in custom software where you control the client but not the upstream API.
How to avoid this:
-
Pin API versions explicitly in your requests. Never rely on the default version; specify it in headers or endpoints.
-
Implement automated schema validation. Use tools like JSON Schema or OpenAPI validators to check responses against a known schema on every call. Log mismatches immediately.
-
Adopt contract testing (e.g., with Pact or Spring Cloud Contract). This ensures both sides agree on the data shape before deployment. Run these tests in CI/CD to catch breaking changes early.
-
Design for graceful degradation. When encountering an unknown field, log it and continue processing known fields. Never crash. Consider a fallback mapping table that can be updated without code deployment.
Quick checklist:
- [ ] API version pinned in all requests.
- [ ] Schema validation active on every response.
- [ ] Contract tests in CI pipeline.
- [ ] Unknown fields handled without failure.
- [ ] Monitoring alerts for schema mismatches.
Mistake #4: Poor Error Handling and Logging
Catching generic exceptions like Exception or Error hides the root cause of tracking failures. When your competitor API returns a 429 (rate limit) or a 503 (temporary outage), a generic handler swallows that context, making it impossible to distinguish between transient issues and permanent data gaps.
What to do instead:
- Use structured error responses. Define custom error classes (e.g.,
RateLimitError,AuthError,ParseError) that carry status codes, retry-after headers, and payload snippets. - Implement retry policies with exponential backoff. For transient errors (5xx, 429), retry up to 3 times with jitter. Log each attempt separately.
- Log with context. Every log entry should include: endpoint, request ID, timestamp, error type, and a correlation ID linking to the original tracking job. Avoid logging raw credentials or full payloads.
- Set up alerting for data quality issues. If a tracked competitor field (e.g., pricing, feature list) fails to update for more than 24 hours, trigger an alert. Use tools like Sentry or Datadog to monitor error rates by endpoint.
Checklist for robust logging:
- [ ] All API calls wrapped in try-catch with specific exception types.
- [ ] Retry policy configured for 429/5xx with max 3 attempts.
- [ ] Logs include correlation ID, endpoint, and error category.
- [ ] Alerting threshold set for >5% failure rate over 1 hour.
Without these, debugging competitor data discrepancies becomes a guessing game—costing you hours of manual reconciliation.
Mistake #5: Failing to Plan for Pagination and Data Volume
Assuming single-page API responses will suffice is a common pitfall. Competitor datasets can be massive—hundreds of pages of product updates, reviews, or pricing changes. Without proper pagination, you’ll miss critical data.
Pagination Pitfalls:
- Offset pagination (e.g.,
?page=2&limit=50) is simple but becomes slow and inconsistent as data changes. New entries shift offsets, causing duplicates or missed records. - Cursor-based pagination (e.g.,
?cursor=abc123) is more reliable for real-time data. It uses a stable pointer (e.g., timestamp or ID) and performs well even with high churn.
Performance Trade-offs:
- Offset pagination is easier to implement but breaks under load. Cursor-based pagination requires more logic but ensures consistency.
- Always check the API’s rate limits and plan for retries with exponential backoff.
Strategies for Incremental Syncs & Backfills:
- Incremental syncs: Use a
sinceparameter or cursor to fetch only new or updated records since the last sync. Store the last cursor or timestamp locally. - Historical backfills: For initial data loads, paginate through all pages in batches. Respect rate limits—use delays between requests.
- Checklist for implementation:
- [ ] Confirm pagination method (offset vs cursor).
- [ ] Test with datasets exceeding 10,000 records.
- [ ] Implement retry logic for 429 (rate limit) errors.
- [ ] Store pagination state (cursor/timestamp) for resumability.
Pro Tip: Always request the maximum allowed page size (e.g., 100 items) to reduce total requests, but balance with memory constraints.
Build Smarter, Not Harder
Avoiding these five API mistakes will save you countless hours of debugging and ensure your competitor tracking system delivers reliable, actionable intelligence. But even the best custom code can’t easily match the breadth of tracking RivalSense provides—covering product launches, pricing updates, partnerships, regulatory changes, and more across hundreds of sources.
Stop wrestling with APIs and start acting on insights. Try RivalSense for free and get your first competitor report today.
📚 Read more
👉 How RivalSense Helped Meta Uncover a Competitor's AI Efficiency Breakthrough
👉 How Internet Sleuthing Revealed a Rival's UX Flaws
👉 2026 Identity Verification Benchmarking: Competitor Matrix Insights
👉 How Financial Insights Drove Key Account Wins: 3 Case Studies
👉 How to Use Competitor Cost Data for Smarter KYC/KYB Strategy